25 MIMIC (and RFA) models
Multiple indicator multiple cause (MIMIC) models are a type of full SEM model where a common factor with multiple indicators is an endogeneous variable, cause by one or more observed variables. Technically, MIMIC models are just full SEM models with single indicator factors as exogeneous variables. What makes MIMIC models especially interesting is that they can also be used to evaluate measurement invariance across groups or across continuous variables (Muthén, 1989). Measurement invariance was defined by Mellenbergh (1998) as:
\[\begin{equation*} f(X|T=t, V=v) = f(X|T=t), \end{equation*}\]which in plain words indicates that the distribution of \(X\) given values of \(T\) (representing what you want to measure) and given values of \(V\) (a variable that possibly violates invariance), should be equal to the distribution of \(X\) conditioned on \(T\) but with varying \(V\). Suppose that \(X\) represents item scores, \(T\) represents mathematical ability, and \(V\) represents gender. In that case, measurement invariance holds if the distribution of the item scores for individuals with the same mathematical ability does not depend on gender. Mellenbergh distinguished between uniform and non-uniform bias, depending on whether the distribution of X given T is uniformly or non-uniformly affected by \(V\). Figure 25.1 shows a graphical display of the relationships between X, T and V in case of unbiased measurement, uniform measurement bias, and non-uniform measurement bias.
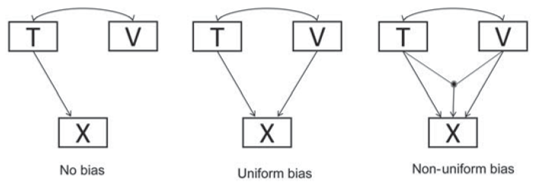
Figure 25.1: Graphical representation of unbiased measurement, uniform measurement bias, and non-uniform measurement bias.
In a MIMIC model, \(T\) is operationalized as a common factor, \(X\) is operationalized as a set of indicators reflective of that common factor, and \(V\) is an observed variable. A MIMIC model that represents indicators of \(T\) that are unbiased (in other words, measurement invariant) with respect to \(V\) is depicted in Figure 25.2. In this model, variable V has solely indirect effects on the indicators. So, if V represents gender, any gender effects on X are the result of gender differences in the common factor.
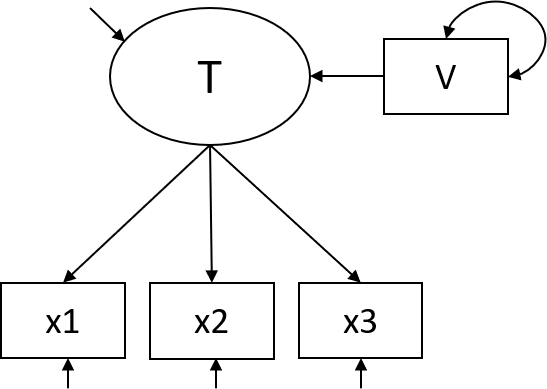
Figure 25.2: A MIMIC model.
25.1 Illustration testing uniform bias in a MIMIC model
The illustration uses data from the open-source psychometrics project Open Psychometrics. Specifically, we used three items from the Humor Styles Questionnaire (HSQ), designed to reflect ‘affiliative humor’. These three items were scored on a 7-point scale ranging from 1 to 7.
- Q5. I don’t have to work very hard at making other people laugh—I seem to be a naturally humorous person.
- Q13. I laugh and joke a lot with my closest friends.
- Q21. I enjoy making people laugh.
library(lavaan)
data <- read.csv("demoData/dataHSQ.csv")
subdat <- data[,c("Q5","Q13","Q21","age","gender")]
subdat <- subdat[subdat$gender%in%c(1,2),]
subdat <- subdat[subdat$age<100,]
subdat <- subdat[rowSums(subdat[,1:3]>0)==3,]
humordat <- subdat
# descriptives of age and gender
min(humordat$age)## [1] 14## [1] 70## [1] 22##
## 1 2
## 574 471## Q5 Q13 Q21 age gender
## Q5 1.000 0.373 0.458 0.054 -0.072
## Q13 0.373 1.000 0.465 -0.089 -0.017
## Q21 0.458 0.465 1.000 0.028 -0.011
## age 0.054 -0.089 0.028 1.000 -0.039
## gender -0.072 -0.017 -0.011 -0.039 1.000The first step when testing evaluating measurement bias with respect to some covariates with a MIMIC model would be to evaluate the factor structure without the covariates. In our example data, there are only three indicators for the construct, so the one-factor model is saturated and its fit cannot be tested.
library(lavaan)
# factor model without covariates
model1 <- '
# define common factor
humor =~ 1*Q5 + l21*Q13 + l31*Q21
# indicator residual variances
Q5 ~~ th11*Q5
Q13 ~~ th22*Q13
Q21 ~~ th33*Q21
# common factor variance (fixed)
humor ~~ humor'
factormodelOut <- lavaan(model1, data = humordat)
summary(factormodelOut, standardized = TRUE)## lavaan 0.6-20.2318 ended normally after 22 iterations
##
## Estimator ML
## Optimization method NLMINB
## Number of model parameters 6
##
## Number of observations 1045
##
## Model Test User Model:
##
## Test statistic 0.000
## Degrees of freedom 0
##
## Parameter Estimates:
##
## Standard errors Standard
## Information Expected
## Information saturated (h1) model Structured
##
## Latent Variables:
## Estimate Std.Err z-value P(>|z|) Std.lv Std.all
## humor =~
## Q5 1.000 0.629 0.607
## Q13 (l21) 0.833 0.063 13.319 0.000 0.524 0.615
## Q21 (l31) 1.028 0.081 12.651 0.000 0.646 0.755
##
## Variances:
## Estimate Std.Err z-value P(>|z|) Std.lv Std.all
## .Q5 (th11) 0.680 0.041 16.556 0.000 0.680 0.632
## .Q13 (th22) 0.451 0.028 16.195 0.000 0.451 0.622
## .Q21 (th33) 0.314 0.033 9.556 0.000 0.314 0.429
## humor 0.395 0.046 8.571 0.000 1.000 1.000Next, we add the variables Age and Gender to the model. The latent variable is regressed on both variables, and Age and Gender are correlated.
# MIMIC model with dummy Gender and continuous Age as covariate
MIMIC_genderage <- '
# define latent common factor
humor =~ 1*Q5 + l21*Q13 + l31*Q21
# indicator residual variances
Q5 ~~ th11*Q5
Q13 ~~ th22*Q13
Q21 ~~ th33*Q21
# common factor variance
humor ~~ humor
gender ~~ gender
age ~~ age
# correlate gender age
gender ~~ age
# regress humor on age and gender
humor ~ b_age*age + b_gender*gender'
## fit model
MIMICgenderageOut <- lavaan(MIMIC_genderage, data = humordat)
## results
summary(MIMICgenderageOut)## lavaan 0.6-20.2318 ended normally after 30 iterations
##
## Estimator ML
## Optimization method NLMINB
## Number of model parameters 11
##
## Number of observations 1045
##
## Model Test User Model:
##
## Test statistic 24.704
## Degrees of freedom 4
## P-value (Chi-square) 0.000
##
## Parameter Estimates:
##
## Standard errors Standard
## Information Expected
## Information saturated (h1) model Structured
##
## Latent Variables:
## Estimate Std.Err z-value P(>|z|)
## humor =~
## Q5 1.000
## Q13 (l21) 0.831 0.062 13.327 0.000
## Q21 (l31) 1.021 0.080 12.692 0.000
##
## Regressions:
## Estimate Std.Err z-value P(>|z|)
## humor ~
## age (b_ag) 0.000 0.002 0.092 0.927
## gender (b_gn) -0.053 0.046 -1.137 0.256
##
## Covariances:
## Estimate Std.Err z-value P(>|z|)
## age ~~
## gender -0.215 0.170 -1.270 0.204
##
## Variances:
## Estimate Std.Err z-value P(>|z|)
## .Q5 (th11) 0.677 0.041 16.487 0.000
## .Q13 (th22) 0.451 0.028 16.212 0.000
## .Q21 (th33) 0.317 0.033 9.683 0.000
## .humor 0.398 0.046 8.603 0.000
## gender 0.248 0.011 22.858 0.000
## age 121.282 5.306 22.858 0.000In order to evaluate whether there are relatively large unmodeled dependencies across Gender or Age and the indicators of humor, you can evaluate correlation residuals.
## $type
## [1] "cor.bollen"
##
## $cov
## Q5 Q13 Q21 age gender
## Q5 0.000
## Q13 -0.001 0.000
## Q21 0.000 0.001 0.000
## age 0.051 -0.092 0.024 0.000
## gender -0.047 0.009 0.021 0.000 0.000## lhs op rhs mi epc sepc.lv sepc.all sepc.nox
## 18 Q13 ~~ age 18.749 -1.138 -1.138 -0.154 -0.154
## 17 Q13 ~~ Q21 5.516 0.872 0.872 2.308 2.308
## 15 Q5 ~~ age 5.247 0.733 0.733 0.081 0.081
## 16 Q5 ~~ gender 4.327 -0.030 -0.030 -0.074 -0.074
## 20 Q21 ~~ age 3.146 0.492 0.492 0.079 0.079
## 21 Q21 ~~ gender 2.390 0.019 0.019 0.069 0.069
## 13 Q5 ~~ Q13 1.770 -0.411 -0.411 -0.744 -0.744
## 14 Q5 ~~ Q21 0.596 -0.341 -0.341 -0.737 -0.737
## 19 Q13 ~~ gender 0.066 0.003 0.003 0.009 0.009The largest correlation residual is found between Age and Q13. The modification indices show that adding a direct effect of Age on Q13 is expected to lead to a drop in the model’s chi-square statistic of around 18.75, and that the standardized expected parameter change is -.15, which could be interpreted as substantial. Therefore, we added the direct effect of Age on Q13 to the model, representing uniform measurement bias with respect to age in the item Q13.
# add direct effect of age on Q13
MIMIC_genderage2 <- c(MIMIC_genderage, ' Q13 ~ age ')
# fit the new model by "updating" the original model
MIMICgenderage2Out <- update(MIMICgenderageOut, model = MIMIC_genderage2)
summary(MIMICgenderage2Out, standardized = TRUE)## lavaan 0.6-20.2318 ended normally after 35 iterations
##
## Estimator ML
## Optimization method NLMINB
## Number of model parameters 12
##
## Number of observations 1045
##
## Model Test User Model:
##
## Test statistic 5.609
## Degrees of freedom 3
## P-value (Chi-square) 0.132
##
## Parameter Estimates:
##
## Standard errors Standard
## Information Expected
## Information saturated (h1) model Structured
##
## Latent Variables:
## Estimate Std.Err z-value P(>|z|) Std.lv Std.all
## humor =~
## Q5 1.000 0.636 0.613
## Q13 (l21) 0.836 0.062 13.470 0.000 0.531 0.624
## Q21 (l31) 1.007 0.078 12.956 0.000 0.640 0.748
##
## Regressions:
## Estimate Std.Err z-value P(>|z|) Std.lv Std.all
## humor ~
## age (b_ag) 0.003 0.002 1.354 0.176 0.005 0.052
## gender (b_gn) -0.054 0.047 -1.152 0.249 -0.085 -0.042
## Q13 ~
## age -0.009 0.002 -4.382 0.000 -0.009 -0.123
##
## Covariances:
## Estimate Std.Err z-value P(>|z|) Std.lv Std.all
## age ~~
## gender -0.215 0.170 -1.270 0.204 -0.215 -0.039
##
## Variances:
## Estimate Std.Err z-value P(>|z|) Std.lv Std.all
## .Q5 (th11) 0.671 0.041 16.490 0.000 0.671 0.624
## .Q13 (th22) 0.438 0.028 15.931 0.000 0.438 0.604
## .Q21 (th33) 0.323 0.032 10.141 0.000 0.323 0.441
## .humor 0.402 0.046 8.720 0.000 0.995 0.995
## gender 0.248 0.011 22.858 0.000 0.248 1.000
## age 121.282 5.306 22.858 0.000 121.282 1.000## $type
## [1] "cor.bollen"
##
## $cov
## Q5 Q13 Q21 age gender
## Q5 0.000
## Q13 -0.005 0.000
## Q21 0.000 0.003 0.000
## age 0.021 0.000 -0.012 0.000
## gender -0.045 0.006 0.022 0.000 0.000## lhs op rhs mi epc sepc.lv sepc.all sepc.nox
## 18 Q13 ~~ Q21 4.588 0.506 0.506 1.344 1.344
## 17 Q5 ~~ gender 4.295 -0.030 -0.030 -0.074 -0.074
## 14 Q5 ~~ Q13 3.297 -0.397 -0.397 -0.732 -0.732
## 22 Q21 ~~ gender 2.288 0.019 0.019 0.067 0.067
## 21 Q21 ~~ age 0.958 -0.335 -0.335 -0.053 -0.053
## 16 Q5 ~~ age 0.934 0.328 0.328 0.036 0.036
## 19 Q13 ~~ age 0.087 1.964 1.964 0.269 0.269
## 23 humor ~ Q13 0.087 0.240 0.378 0.322 0.322
## 15 Q5 ~~ Q21 0.087 -0.127 -0.127 -0.272 -0.272
## 20 Q13 ~~ gender 0.087 0.003 0.003 0.011 0.011
## 29 gender ~ Q13 0.087 0.008 0.008 0.014 0.014
## 24 Q13 ~ gender 0.087 0.014 0.014 0.008 0.008Exact fit is not rejected for the modified MIMIC model (\(\chi^2(3) = 5.40, p = .132\)), and there are no correlation residuals larger than .10. We therefore do not modify the model further.
The results show no significant gender or age differences in the common factor humor. The statistically significant direct effect of Age on Q13 of \(\hat{\beta} = -.123\) indicated that for equal levels of ‘humor’, older respondents provided less positive responses to this item. To interpret this uniform bias, we would have to reflect on attributes that are specific to this item (as opposed to the other 2 items) that could cause less positive responses by older people. In this example, the item refers to laughing and joking a lot ‘with my closest friends’, while the other two items do not refer to specific types of social company. Since younger people may be spending more time with their closest friends (in school for example), than older people (who spend relatively more time with colleagues and family), the age bias in item Q13 may be explained by these differences in social environment.
25.2 Evaluating non-uniform measurement bias
The direct effects of covariates on items in a MIMIC model represent uniform measurement bias. In a multi-group model, uniform measurement bias would be reflected by unequal measurement intercepts across groups. Non-uniform bias is reflected by unequal factor loadings across groups in a multigroup model. In a MIMIC model, moderation of factor loadings by a covariate would be represented by an interaction effect of the common factor and the covariate on an indicator (Woods & Grimm, 2011). Since we cannot directly observe the common factor scores, simply calculating each person’s score on the Factor*covariate product variable is not possible. Alternative options to evaluate non-uniform measurement bias in MIMIC models are using latent moderated structures (Klein & Moosbrugger, 2000), which however leads to inflated type 1 error rates or the product indicator approach, which has better performance (Kolbe & Jorgensen, 2017).
25.3 Connection with measurement invariance testing in multigroup models
In situations where the covariate is a grouping variable, meaurement invariance can also be tested in a multigroup model. For example, if variable \(V\) in Figure 2 represents gender (0 = boy 1 = girl), one could evaluate measurement invariance using either a MIMIC/RFA model, or a multigroup model. A large difference between the two approaches is that in the multigroup model without equality constraints, all parameters are uniquely estimated in the two groups. So, not only the factor loadings and intercepts, but also the residual variances and the factor (co)variances are unconstrained in the configural invariance model. There is no such equivalent in the MIIMIC model, because the MIMIC model is fitted to the total sample of boys and girls together. There will be only one set of estimates for residual variances or factor variances, implying that those parameters do not differ between boys and girls.
Moreover, in A MIMIC model it is not possible to regress all indicators on \(V\) simultaneously because such a model would not be identified. The MIMIC model needs so-called ‘anchor items’ that are assumed to be invariant and are therefore not tested. Selecting these anchor items is not an easy task (Kolbe & Jorgensen, 2019).
In the example analysis provides above, we started with a MIMIC model that represents no measurement bias (none of the indicators was regressed on \(V\)), and then used correlation residuals to identify whether any effects of V on indicators should be included. The starting point was thus the most constrained model, and we freed parameters when deemed necessary. A similar approach could be taken in a multigroup model by starting with a model that represents strong factorial invariance, and releasing equality constraints when necessary. By taking this approach one is effectively using all remaining indicators as anchor items.
25.4 RFA-models
Restricted Factor Analysis (RFA) models (Oort, 1992) are statistically equivalent to MIMIC-models. The only difference is that in RFA-models the common factor is correlated with the covariates, instead of regressed on the covariates.
References
Klein, A., & Moosbrugger, H. (2000). Maximum likelihood estimation of latent interaction effects with theLMS method.Psychometrika, 65, 457-474.
Kolbe, L., & Jorgensen, T. D. (2017, July). Using product indicators in restricted factor analysis models to detect nonuniform measurement bias. In The Annual Meeting of the Psychometric Society (pp. 235-245). Springer, Cham.
Kolbe, L., & Jorgensen, T. D. (2019). Using restricted factor analysis to select anchor items and detect differential item functioning. Behavior Research Methods, 51(1), 138-151.
Muthén, B. O. (1989). Latent variable modeling in heterogeneous populations. Psychometrika, 54(4), 557-585.
Oort, F. J. (1992). Using restricted factor analysis to detect item bias. Methodika, 6(2), 150-166.
Woods, C. M., & Grimm, K. J. (2011). Testing for nonuniform differential item functioning with multiple indicator multiple cause models. Applied Psychological Measurement, 35, 339-361.